On 13 March, the BitMEX platform was subject to two distributed denial-of-service (DDoS) attacks at 02:16 UTC and 12:56 UTC. These attacks delayed or prevented requests going to and from the BitMEX platform, causing direct disruption to our users. Following these incidents, we have been working around the clock to gather the facts and post mortem the incident.
For the moment, I’d like to share some further details and answer the immediate concerns of our users since the service went down, what happened, and the steps we’re taking to enhance the security of our platform.
Here’s a brief summary of what happened and how we responded to the 13 March DDoS attacks.
- At 02:16 UTC a botnet began a DDoS attack against the BitMEX platform. We discovered shortly afterward that this botnet had been responsible for a similar, yet unsuccessful, attack a month before on 15 February. Based on our access logs, we believe the attackers identified their target in February, then waited for the moment their attack would make the most market impact.
- On 13 March during a peak moment of market volatility, the botnet overwhelmed the platform via a specially-crafted query to the Trollbox feature, prompting the database’s query optimiser to run an extremely inefficient query plan. See below for more details.
- Our security team saw database CPU usage reach 100%, with 99.6% of that CPU IO wait (an idle state). At the time, we misdiagnosed this as a failed disk, believing it to be a hardware failure with our cloud provider. EBS volume failures often display similar performance characteristics.
- The DDoS caused the processing of messages in our API layer to slow down, delaying them from hitting our trading engine. Once the DDoS attack had been identified and stopped, the API was able to send messages to the trading engine without delay.
- 10 hours later, we received the same attack at 12:56 UTC. In both cases, our traffic filtering systems found and blocked the traffic, but the traffic built up a significant internal queue. Learning from the first incident, we cleared the queue manually to resume system operations.
- Live updates were published at https://status.bitmex.com, and respective site announcements were made to communicate the incident.
- As part of our internal post mortem, the BitMEX team identified 156 accounts for which Last Price stops were clearly erroneously triggered on ETHUSD, caused by the unintended late processing of market orders during the first downtime at 02:16 UTC. For each stop that triggered erroneously during this period, BitMEX calculated the delta to the printed Index Price and refunded the user. A total of 40.297 XBT was refunded.
Is my account and personal financial data safe?
The security and safety of user data are our highest priority. There is no threat to individual personal information because a DDoS attack is not a hack. It is a distributed effort to slow down a system by overwhelming it with requests. User data remains secure.
Why do you suspect these attacks are related?
Our security team has analysed the traffic patterns of both attacks and identified significant commonalities between them. We believe that both the 13 March and 15 February attacks were orchestrated by the same actor. We continue to monitor for recurrences of this activity and have taken steps to proactively block further impact.
Why was the Trollbox vulnerable to a DDoS attack?
The Trollbox (chat box) is one of the first features we coded at BitMEX and it has since become a well-known anchor of the site. It is where we spent a lot of time talking to our customers in the first years of the platform, talking about anything: new products, feedback, UI improvements, and general nonsense.
Yet on 13 March, this became an attack vector. Here’s the technical explanation: the chat has seven languages, each with a simple channel ID of 1-7. First is English, and the last two are Spanish and French. We’ve been working on whole-site translations for those two, but they’re in our development queue.
The /chat endpoint allows for querying the last 100 rows by channel ID. There is an index for this, but the query optimiser rarely uses it due to its low cardinality. Given the size of the table (about 50 million rows), it’s actually faster to do a reverse sequential scan, then filter. The query optimiser has the ability to discriminate and build different query plans based on channel ID, but to do so, it needs up-to-date statistics. It gets those statistics via an ANALYZE (or VACUUM ANALYZE), which was not running frequently enough in this environment.
Therefore, the query optimiser held to its gameplan and performed reverse sequential scans for all languages, until it finally found 100 rows to return. In the case of Spanish, it had been a very long time since anyone had chatted. How long, in fact? It scanned 849,748 rows before it found enough that matched the criteria:
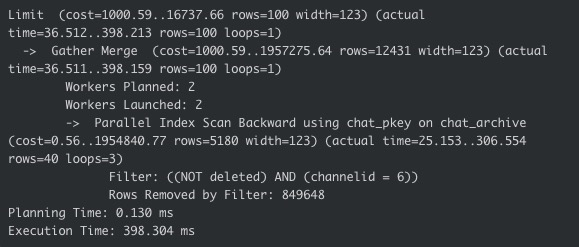
This expensive sequential scan allocated and deallocated large amounts of memory rapidly, spilling over to disk and rapidly overwhelming the system with syscalls. At the time of the attack, the database was only spending 0.6% of its time servicing requests and the other 99.4% on IO wait. This caused all queries, not just /chat queries, to be extremely slow.
How does an attack on chat storage affect trading?
BitMEX operates a platform where data is segregated: data related to users (emails, activity, chats, login events, etc.) are separated from trading data (positions, executions, margin, etc.). But the chats relate to users, as do access tokens and API keys. That means this resource exhaustion caused serious problems at the authentication and access control layer, which sits in front of the trading engine. The trading engine was operating normally and market data was not disrupted, nor were deposits and withdrawals. But it became nearly impossible to reach the engine during these periods, leading to the serious degradation in service.
Could this attack happen again?
No system is immune to disruption via DDoS. There are many techniques that can be employed to reduce or eliminate impact. We have fixed the underlying issue and have been working around the clock to introduce additional detection and response layers. Additional efforts are underway to increase automated scalability under load and to further isolate critical systems.
What is BitMEX doing to enhance security?
As part of the ongoing monitoring and mitigation efforts mentioned above, our security team is reviewing the oldest and, therefore, most vulnerable parts of the system to simplify, de-couple, improve performance, and isolate systems.
At the same time, the team is developing the public-facing protocols around downtime, market suspension, resumption, and communication. This will provide even greater transparency for our users if we face any disruption to our service in the future.
Some traders have accused BitMEX of causing the outage on purpose – how do you respond?
We operate a fair and efficient platform. Trading downtime degrades the experience for all customers and reduces our stature in the market. It would be against our own interests to fabricate downtime. That said, it is clear that the community wants to know more about how liquidations interact with the Insurance Fund, especially in this very demanding scenario. We will share more details about this very soon.
In the coming days, we will publish a series of posts about what went wrong and the steps we are taking. Aside from me, you will hear from other leaders of our business.
As always, you can ask us anything by contacting support.
Thanks,
Arthur Hayes
Co-Founder & CEO