Writen by BitMEX Grantee Calvin Kim
Abstract: Bailey and Sankigiri, in their paper “Merkle Trees Optimized for Stateless Clients in Bitcoin” present a new accumulator design for storing bitcoin state, claiming a dramatic improvement over previous work in Utreexo. However, we have identified flaws in the code used to claim these improvements. We show a bug in the code that invalidates the findings presented in their paper. The authors were made aware of the error on April 23rd, 2022.
The main claim from Bailey and Sankigiri’s paper is “that the new algorithm” achieves a 4.6x reduction in proof size vis-a-vis UTREEXO”. The paper presents the following plot comparing the proof sizes block by block.
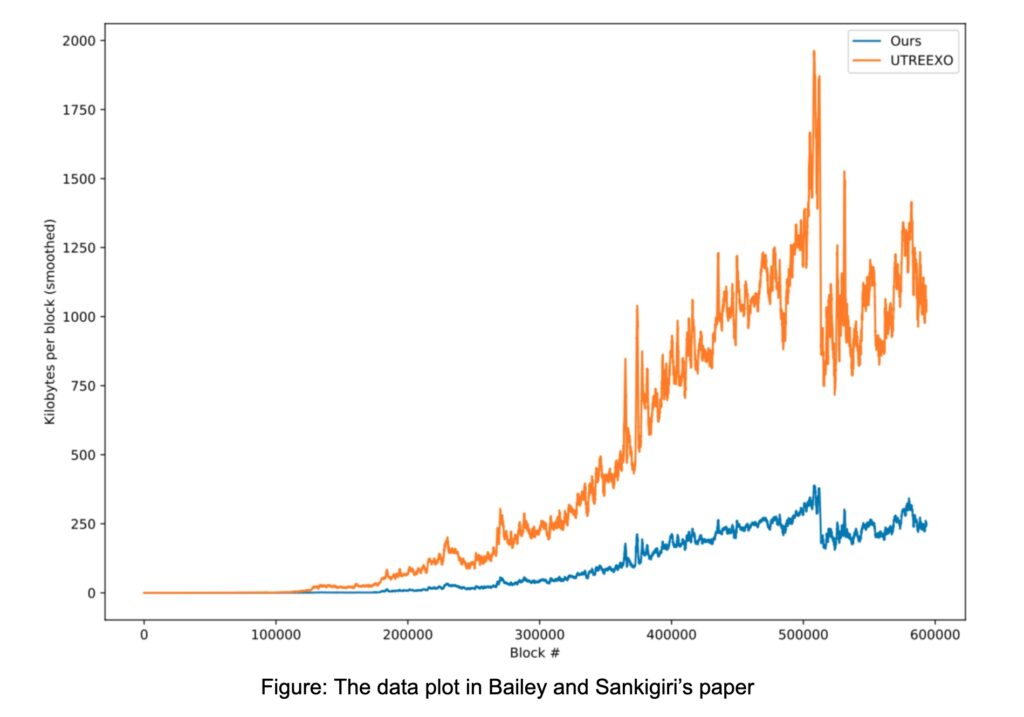
Figure: The data plot in Bailey and Sankigiri’s paper
The bug we’ve identified exists in RetrieveListProofs() up until commit `6f1b3c0a08eaf8b84715aa3eecf236e61e3b7c98`. This function takes in a slice of elements to be proven in the accumulator and returns the proof for each one of those elements. However, the goroutine they’ve used only ends up proving the last element in the slice. This is demonstrated in a playground link here: https://go.dev/play/p/BoMuRWEnAf1. The function ends up only proving the last element of the slice as the last element is proven n times (where n is the length of the slice) and duplicate proof hashes get removed in the caller, `RetrieveBatchProof()`.
The bug was fixed in commit `8e85f455a7fdf087e0cb3098ccf12dabf10764ad`. We’ve generated the below plot using the code cited in the paper with the code from the current master on commit `d9a12423cd4c5903dcba3498d17e01d76dea34d4`:
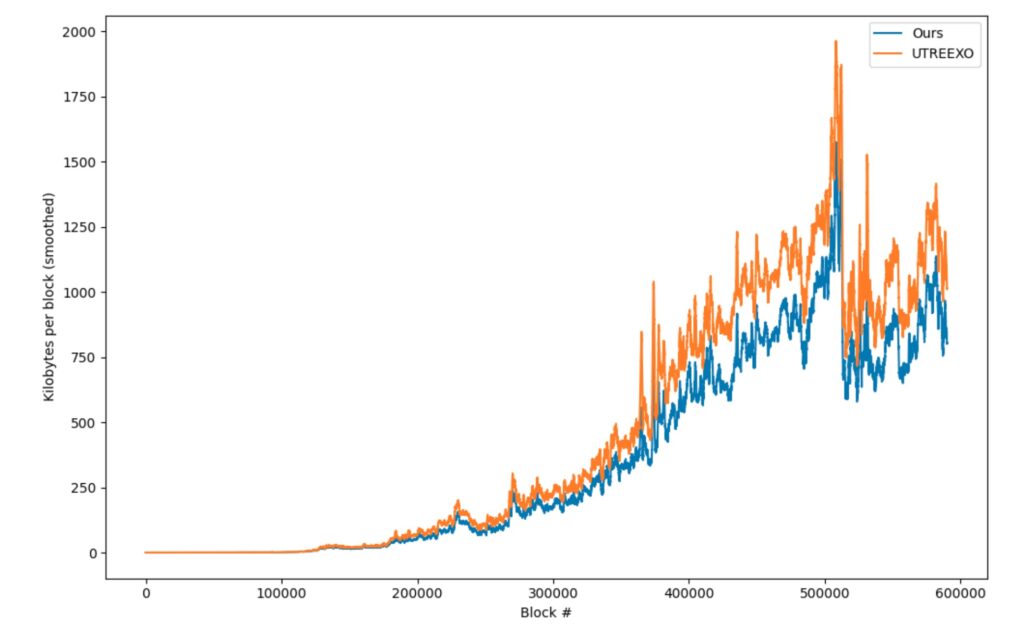
Figure: Data plot up to block 591,000 with the bug addressed
This new code shows a much smaller proof size savings of 22.17%. However, this is not the graph published on their paper and the graph they’ve included in the paper was generated with the buggy code.
It should be noted that the code to generate the data for this plot was buggy as well and would crash when attempting to reproduce the results in the paper. The authors were contacted and subsequent commits have been made to the repository linked in the paper. However, the code was still not completely bug free after the revisions and the patch and the script here is required to generate the graph.
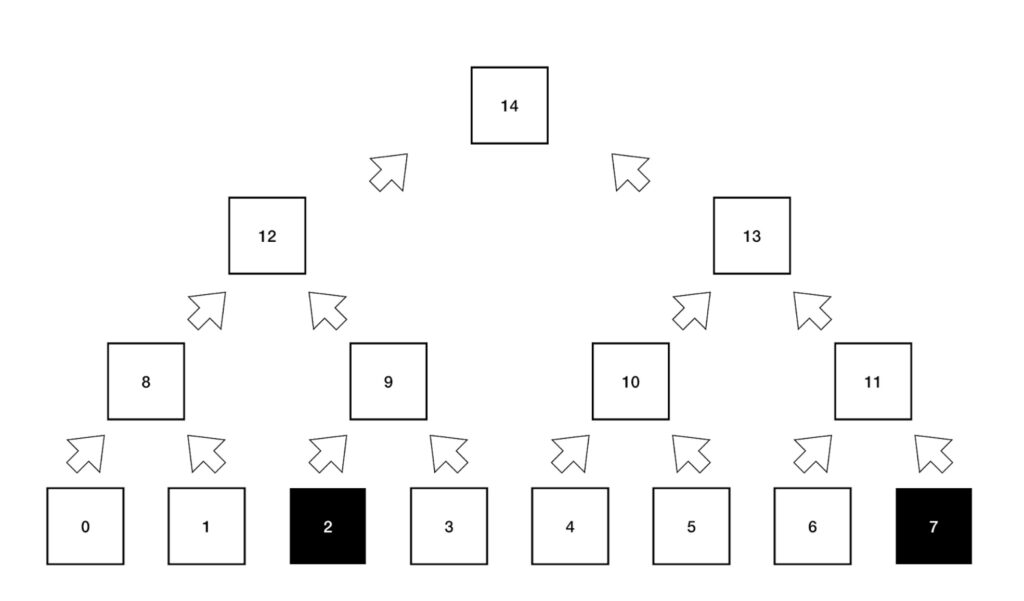
The file in this gist can be added to the “patriciaaccumulator” package to verify that the code has the aforementioned bug. The test code generates an accumulator with 8 leaves and proves leaves 2 and 7.
In the code without the bug, 4 proof hashes in positions: 3, 6, 8, 10 are returned. The code with the bug only proves the last leaf 7. Thus only 3 hashes are returned: 6, 10, 12.
The idea that was presented in Bolton and Sankagiri’s paper does lead to proof savings over what was originally proposed in the Utreexo paper by Dryja. However, the results claimed in the abstract of the paper are incorrect and are based on buggy code. The correct data presented here achieve savings of 22.17% and the correct plot is significantly different from the one presented in the paper.