In Part 1 of this series, we told stories of the origin of BitMEX.
Today, we’re offering Part 2 of this series – a deep dive into overload and problems inherent to horizontal scaling. We will discuss the results from our efforts so far in handling unprecedented volumes and will detail the parts of the BitMEX engine that must remain serial, the parts that can be parallelised, and the benefits of BitMEX’s API-first design.
In Part 3, we’ll explain code optimizations that have already been put in place, systems that have been parallelised, and why certain features have been removed. Additionally, we’ll talk about BitMEX’s commitment to fair and equal access – and how that translates to our refusal to offer co-location.
Let’s get started.
Growth
BitMEX is a unique platform in the crypto space. In order to offer industry-leading leverage and features, the BitMEX trading engine is fundamentally different than most engines in crypto and in traditional finance. And while we’re able to offer exceptionally accurate trading and margining, it hasn’t been particularly fast – yet.
Throughout 2017, BitMEX’s average daily trading volume grew by 129x. This is incredible growth, and it continued to grow throughout 2018 and 2019.
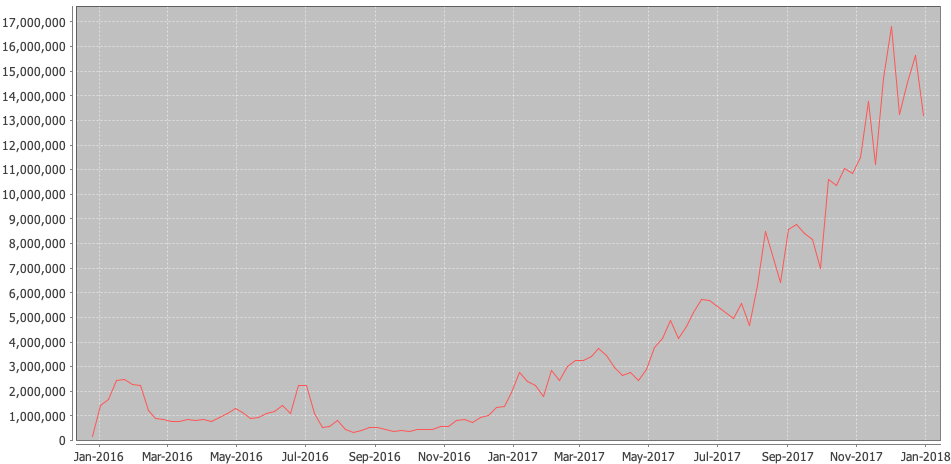
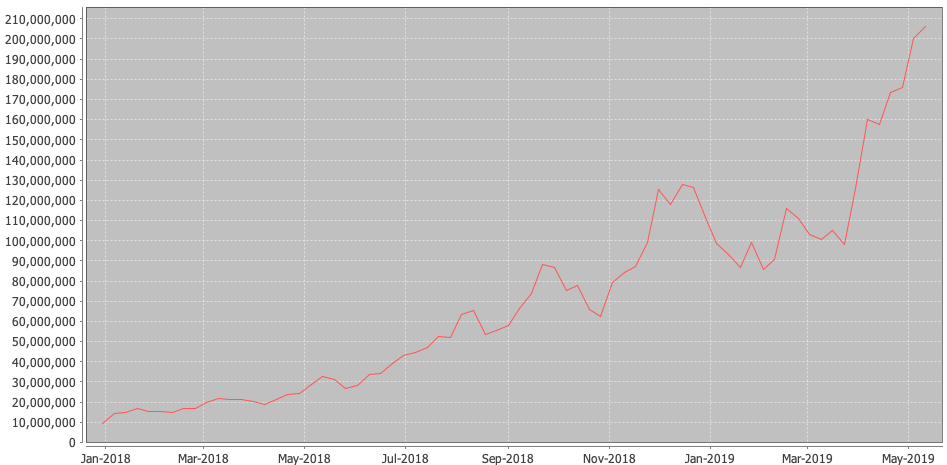
Notice that this chart begins at the peak of the last chart’s end.
As you can see above, orders per week have also sharply increased from 2017. Of particular interest is that an all-time USD trading record of $8B was hit in July 2018, despite the lower order rate! This record wasn’t broken until just last week, on 11 May 2019, where $11B was traded. These records still stand for the most ever traded in a day by a crypto exchange, and the XBTUSD Perpetual Swap is the most-traded crypto product ever built. It has since been imitated over a dozen times by crypto exchanges, both aspiring and established.
In May 2018, we began a focused effort to optimize order cancellation, amend, and placement actions in the trading engine, reworking internal data-structures, algorithms and audit checks to tune specifically for the kind of speed kdb+ can offer. This was a hyper-focused effort to make the existing trading engine continue to do what it does, only a lot faster. We’re very proud to say that this effort yielded us over 10x performance improvement in a very short time, with 4.6x achieved in just the first 30 days, and 10x by the end of August. By mid July, the performance enhancements delivered to the trading engine had resulted in the elimination of virtually all overloads, and we’re very proud of our technology teams for achieving this amazing result.
Below, overloads as a percentage of all write requests (order placement, amend, cancel). More red = more overloads.


The market reacted to the increased capacity, pushing BitMEX volumes into the stratosphere. We had the crypto industry’s first-ever million bitcoin trading day. The spare capacity enabled us to continue to launch innovative new products like the first ever ETHUSD quanto perpetual swap, which became the number 1 traded ETHUSD product within 6 weeks of listing. In November 2018, we nearly touched two million bitcoin in 24 hours and achieved $11B in trading in May 2019.
While the July graph looks completely clear, if you’re reading this, you know that it didn’t stay that way. Why isn’t it completely fixed? Why haven’t we simply continued that effort to get to 100x and beyond?
Let’s get into some background.
Queuing
Servicing requests on BitMEX is analogous to waiting in line at a ticket counter. You join the queue, and when the queue clears, you make your request.
How long does it take to buy a ticket? Well, if there’s no queue, it’s going to be very quick. The entire interaction lasts only as long as it takes to service your individual request. This is why some other trading services, which have significantly lower traffic and volume, may feel snappier even if their maximum capacity is lower: there are fewer requests in the queue.
Consider what happens when the queue is very long. Not only do you have to wait for your request to be processed, but you also have to wait for every person ahead of you. You could have the world’s most efficient clerks, but if a queue starts forming, the average experience is going to be very poor.
Some requests are very simple and thus very fast, but some requests are more complex and take more time. If a request can be avoided altogether (say, the user doesn’t have enough available balance to complete it), optimisations can be employed to ensure it never even joins the queue, similar to automated check-in counters and bag drops.
Traffic on a web service behaves in many of the same ways. Even when processing an individual request is very fast, when a queue forms for a single resource, the experience degrades.
You’ve seen this before. Amazon and Alibaba have had major downtime on holidays. Twitter had the infamous failwhale. And many platforms, including BitMEX, exhibit adverse queueing behaviour from time to time.
Overload
“System Overload”, as you might know it, is one mechanism we at BitMEX use to address this problem. Are you shaking your head? How could overload be the solution, not the problem? Overload is a defence mechanism, better known in the industry as “load shedding,” a technique used in information systems to avoid system overload by ignoring some requests rather than crashing a system and making it fail to serve any request.
We’ve published a document showing the definitive rules around load shedding and explaining the mechanism:


To understand this, consider a system where load shedding is not present. With increasing demand, a queue forms and begins to grow.
How bad can it get? When the market moves, giant swarms of traders race to place orders to increase or decrease their position. One might think that the delay would regulate itself: as service quality decreases, traders will start placing orders at a slower pace, waiting for each one to confirm before placing the next. But in fact the opposite happens: as response time increases, automated arbitrageurs are unable to step in quickly to keep the prevailing price in line with other exchanges. Other savvy traders attempt to manually trade the perceived difference in pricing, which further escalates the size of the queue.
Without safeguards, the queue can reach delays of many minutes. Orderbook spreads increase as users fail to effectively place resting orders. A great market price becomes a terrible one by the time an order actually makes it through the queue and executes. In this environment, trading is effectively impossible. This isn’t just hypothetical; it is a common issue also faced by other crypto markets.
BitMEX’s solution to this is to limit the maximum number of order management requests that can be in queue for the trading engine. There is a service in front of the trading engine that identifies requests as reads (i.e. data fetches, like GET /api/v1/position) and writes (e.g. order placement/amend/cancel, and leverage changes). If it is a write, it is delegated to the main engine, and a queue forms. If this queue gets too long, your order will be refused immediately, rather than waiting through the queue. The depth of this queue is tuned to engine performance to cap latency at a worst-case latency of 3-5 seconds.
As per our Load Shedding documentation, certain types of requests like cancels are allowed to enter the queue no matter its size, but they enter at the back of the queue, like any other request.
The result: traders know immediately that the system is experiencing lags, rather than finding out after the order is in the queue, taking many seconds to execute. The engine isn’t slowing down: in fact, during overload, the engine reaches a peak order rate, and the orderbook and trade feeds move very quickly.
Trading During Overload
Some traders have expressed frustration that trading continues during overload. In fact, we’ve seen many conspiracy theories on Twitter and in trader chat rooms about it, arguing that this must be because certain traders have unequal access to the system. That is fundamentally untrue: every single trader on BitMEX has equal access and enters the back of the same queue. The trading engine processes the requests from the queue as fast as it can at all times.
If the number of orders entering the system is 5 times what the system can handle, only 20% of orders will be accepted and 80% will be rejected. As to which orders are rejected and which are accepted, it is simply whether there is space in the queue at the moment when the order arrives. If your request happens to hit the queue just after a response has been served, bringing the queue below the maximum depth, it will be accepted. The next order submitted after yours may not be.
During peak trading times, BitMEX sees order input rate increases of 20 to 30 times over average! Executed trades have reached peaks of over $100M/minute. This rate, if sustained, would lead to $6B trading volume per hour, or over $144B per day! This is 13x the top volume ever recorded in a single day on BitMEX, or on any other crypto platform.
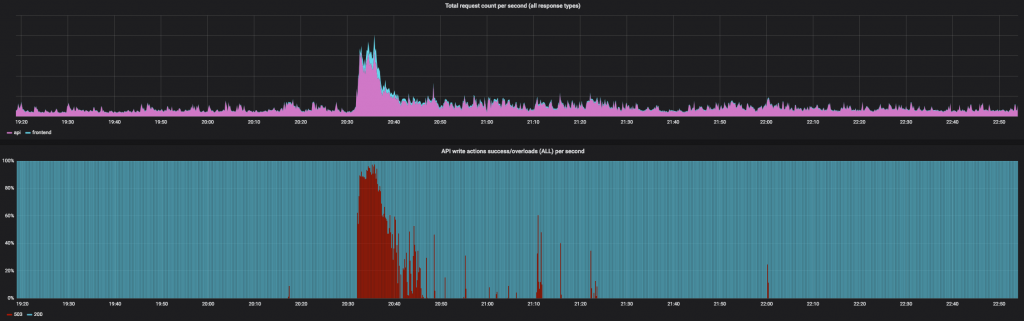
Bottom: Percentage of orders rejected per 10-second slice. This example shows an unusually high percentage, indicating a worst-case overload. In practice, only 2-3% of all orders submitted to BitMEX per day are rejected by load shedding.
In order to always provide a smooth trading experience, BitMEX needs to have a large reserve of capacity to handle these intense events. Below, we’ll document some of the challenges we’ve faced in achieving this goal.
High Scalability & Amdahl’s Law
How do scaling problems get solved? There are two types of scaling: “vertical”, and “horizontal”. Scaling vertically involves making an individual system faster. You can do this by buying a faster processor (good luck; Moore’s Law for CPUs is dead), or by finding ways to do less work. On the other hand, scaling horizontally is of the “throw more money at it” variety: spin up more servers, and spread the load among them.
Web servers are a good example of a horizontally-scalable service. In most properly-architected systems, you can add more web servers to handle customer demand. When one reply does not depend upon another, it is safe for servers to work in parallel, like check-out clerks at a grocery store.
This is a massive simplification, but for many, the scalability solution is a longer version of “throw money at the problem”. Many systems scale horizontally. Most customers’ experiences are completely independent of one another, and can simply be served by more web servers. The backing databases often can be scaled horizontally, replicating their data to one another.
There’s a limit to how much horizontal scaling is possible, which is often expressed as Amdahl’s Law. In short: a system’s horizontal scalability is limited by the serial operations (or the operations that must happen in a specific sequence) required. To illustrate: imagine a simple, single-threaded service you want to speed up by running it in parallel e.g. through multiple servers. Through some performance analysis, you find that only 25% of the work must be done in-order. The rest can be done in parallel. This means that, no matter how many cores or servers you throw at the problem, it can only be sped up by 4x, as 1/25% = 4. That bit of serial work becomes the bottleneck.
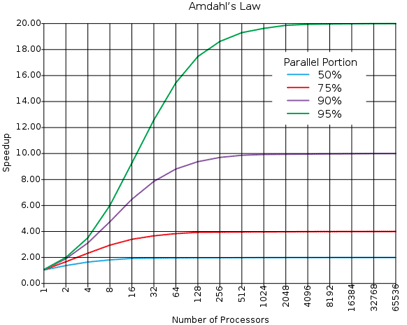
This serial requirement is where BitMEX vastly differs from most general web services. The BitMEX trading engine has far more serial requirements, thereby seriously limiting parallelisation opportunities.
Sequential Problems: Orders and Re-margining
The BitMEX trading engine processes orders in a sequential, First-In-First-Out (FIFO) fashion. Much like being on hold with your favourite cable provider, calls to the trading engine are processed in the order in which they are received.
This is a fundamental principle to a market and cannot be changed. Orderbooks must have orders applied to them sequentially – that is, the ordering matters. When an aggressive order is placed, it takes liquidity out of the book and no other order may consume it. For this reason, matching on an individual market cannot be effectively distributed; however, matching may be delegated to a single process per market.
At the time of writing, BitMEX operates approximately 150 API servers talking directly to a proxy in front of the engine. This proxy delegates read requests to data mirrors, websocket data to the pub/sub system, and write requests directly to the engine.
Writes are, as you might expect, the most expensive part of the system and the most difficult to scale. In order for a trading system to work effectively, the following must be true:
- All participants must receive the same market data at the same time.
- Any participant may send a write at any time.
- If this write is valid and changes public state, the modified world state must be sent to all participants after it is accepted and executed.
Unoptimised, this system undergoes quadratic scaling: 100 users sending 1 order each per minute generates 10,000 (100 * 100) market data packets, one for each participant. A 10x increase to 1,000 users generates 100x the market data (1000 x 1000), and so on.
As mentioned at the beginning of this article, BitMEX grew 129x in 2017. During that time, our user-base scaled proportionally. This means that, on December 31, 2017, compared to January 1 2017, we were sending roughly 16,641x (129 * 129) more messages.
System Consistency
Scaling BitMEX is a difficult undertaking. We aren’t a typical spot or derivatives platform: we handle the entire customer lifecycle, from sign-up, to deposit, to trading.
In order to offer 100x leverage safely, BitMEX’s systems must be correct and they must be fast. BitMEX uses Fair Price Marking, an original and often imitated system by which composite indices of spot exchange prices underlying a contract are used to re-margin users, rather than the last traded price of the contract. This makes BitMEX markets much more difficult to manipulate by referencing external liquidity.
In order for this to work properly, the BitMEX engine must be consistent. Upon every mark price change, the system re-margins all users with open positions. At this time, the entirety of the system is audited by a control routine. The cost of all open positions, all open orders, and all leftover margin must be exactly equal to all deposits. Not a single satoshi goes missing, or the system shuts down! This happened a few times in our early days; each time due to a few satoshis’ rounding error on affiliate revenue or fees. While there was temptation to build in a small buffer of funds in case of error, our team believes system solvency to be paramount: they hold themselves to the highest possible standard. The system still audits to an exact satoshi sum today after every major change in state.
It is not possible for a malicious actor with database access on BitMEX to simply edit his or her balance: the system would immediately recognise that money had appeared from nowhere, emit a fatal error, and shut off.
Before auditing, the current value of your entire account must be recalculated from scratch; that is, the value of all your open positions and open orders at the new price. This ensures traders are not able to buy what they cannot afford. Traders don’t reach negative balances on BitMEX.
Speeding up this system is one of the primary goals of our scaling effort. Matching takes comparatively little time and scales easily; margining does not. BitMEX has always strived for “correct first, fast later” – and thus, the time this has taken is largely due to our commitment to getting it right. Incorrect results are not tolerable, and therefore a correctly distributed system must be able to detect slow or failed producers, rebalance load, and complete essential processing within a tight time budget. This requires careful, methodical attention and rigorous testing.
Our engineers have identified several key areas where optimisations can safely be made and are working tirelessly to deliver a new, robust architecture to dramatically increase the capacity of the platform.
API-First Design
BitMEX is rather unique among its peers: it was implemented API-first. The BitMEX architecture is comprised of three main parts: the trading engine, the API, and a web frontend. Notice that we didn’t use the term “the” frontend. Why is that?
When building BitMEX, we wanted our API to be best-in-class. A great API makes it easy for developers to build robust tools. It even enables alternate visualizations and interfaces that we may never have imagined. At the time we began coding, it was generous to say that crypto trading APIs were less than subpar. Many were missing any semblance of regularity, documentation or pre-written adapters, critical data was often missing, and vital functions could only be done via the website. Worse yet, most didn’t even have websocket feeds, and the few that did often kept them private and only accessible via the website.
At BitMEX we bucked the trend and set a new standard for crypto trading APIs. We engaged in a deliberate policy of dogfooding, by stipulating that the website must use the API as any other program might use it. This means there is not “the” frontend, there is simply an official BitMEX frontend. The BitMEX website, as a project, has no special access other than the ear of the API developers and a few login/registration anti-abuse mechanisms.
This also means that no mechanism for accessing BitMEX is faster or slower than another. All users enter the same data path and the same queues, whether they are accessing via a mobile device, a browser, a custom-written API connector, or even through Sierra Chart’s DTC integration. This ensures a fair experience for everyone.
From the beginning, BitMEX had:
- A websocket change feed for all tables, including orders, trades, orderbook, positions, margin, instruments, and more, where all tables follow the same format,
- A fully documented API, both usable by humans and by machines via the Swagger spec (now referred to as OpenAPI),
- Multiple example projects on GitHub, and
- A unified data path for both website and API consumers.
Real-Time Data
BitMEX’s commitment to API-first design shines in its implementation of real-time data, which is exposed through our websocket. As mentioned above, all tables have real-time feeds available, a first in the crypto industry and extremely rare today. Additionally, all tables follow the same formatting, meaning you can write as little as 30 lines of code to be able to process any stream. Or, use one of ours off-the-shelf from GitHub.
This data flows from a change stream generated by the engine itself, which is filtered for individual user subscriptions. This allows for a very comfortable flow when building interfaces on top of BitMEX: subscribe to your tables, make requests, and listen on the stream for changes. Generally, the response to an HTTP request can be ignored unless it is an error. This avoids a common duality in applications where both websocket streams & HTTP responses must be read separately and coalesced, resulting in awkward code and bugs.
We believe that this philosophy of building a top-tier application interface not only makes for the best userland integrations, it makes the BitMEX website and upcoming mobile apps the best they can be.
Our real-time feeds are of paramount importance to the orderly functioning of the BitMEX platform. To that end, we are staging a major internal rework of this system that we expect to improve latency and throughput significantly, without external changes. We will announce that launch and its results soon.
Next Steps
We hope the above has given all of you an idea of the challenges BitMEX faces while scaling the platform for the next 100x growth. While we are proud of the platform’s success and thankful to our users, we need to continue to improve in order to be viable in the years to come.
The BitMEX Trading Engine Team releases updates to the platform multiple times per week. These incremental changes are both part of the ongoing longer term re-architecture of the trading platform as well as tactical in-place capacity improvements to the engine. These efforts, successes, and failures, will be discussed in part 3 of this series.
Our Engine Team has been able to deliver major upgrades to our system’s throughput on a regular cadence. Just recently, on 23 May 2019, the team pushed through a major infrastructure upgrade that increased the new order handling capacity by up to 70%. Significant capacity improvements like these will continue to be delivered over the coming months whilst the larger scale re-architecture of the platform continues in parallel.
While work proceeds quickly on scaling our trading engine, we are also scaling our teams. BitMEX employs both world-renowned experts in electronic trading systems, scaling, infrastructure, security, and web, and has junior and intermediate roles for people who aren’t afraid to learn and get their hands dirty. If this article interests you, you might be the kind of person we want on our team; take a look at the exciting opportunities on our Careers Page.