Abstract: In this piece we attempt to compare and evaluate the differences in the blockchain size and data storage requirements, for Bitcoin and Ethereum. Surprisingly Bitcoin’s blockchain is still larger than Ethereum, however this is about to change and Ethereum is soon set to surpass Bitcoin with its rapid appreciation in blockchain size. On the other hand, this metric is not a particularly useful comparison, as to learn useful information about the Ethereum network one needs to perform significantly more computations and generate far more data.

Bitcoin vs Ethereum Blockchain: Overview
Bitcoin journalist and podcaster Peter McCormack recently tweeted a comparison between the storage required by a full Bitcoin node, compared to a full Ethereum node. The lead developer of the Geth implementation of Ethereum, Peter Szilagyi, retweeted the post with a different comparison.
The first question this brings up is how can the Ethereum chain be so small, at only 175GB? After all, transaction throughput on Ethereum is higher than Bitcoin. Ethereum has also lately become a beast, with huge demand for Defi and NFT related activities. It seems weird that all this data is only a few hundred GB. Especially considering that almost any action a user takes on Ethereum requires a digital signature, which takes up a lot of space.
Ethereum is currently therefore generating far more data than Bitcoin, however Bitcoin still has more cumulative blockchain data, as the chart below shows. From 2015 to 2018, Bitcoin’s blockchain grew at a faster rate than Ethereum, then from 2018 to 2020 they seemed to grow in parallel. Finally, from late 2020 onwards, the Ethereum blockchain growth rate accelerated further and the growth rate is now far higher than Bitcoin. Ethereum’s cumulative blockchain size looks set to shortly overtake Bitcoin and accelerate far beyond it. While it may be surprising to learn that the Ethereum blockchain is smaller than the Bitcoin blockchain, it seems that it is a bias towards the present and failure to remember just how small Ethereum was a few years ago, which is the primary cause of this surprise, in our view.
Bitcoin vs Ethereum (Blockchain size (GB))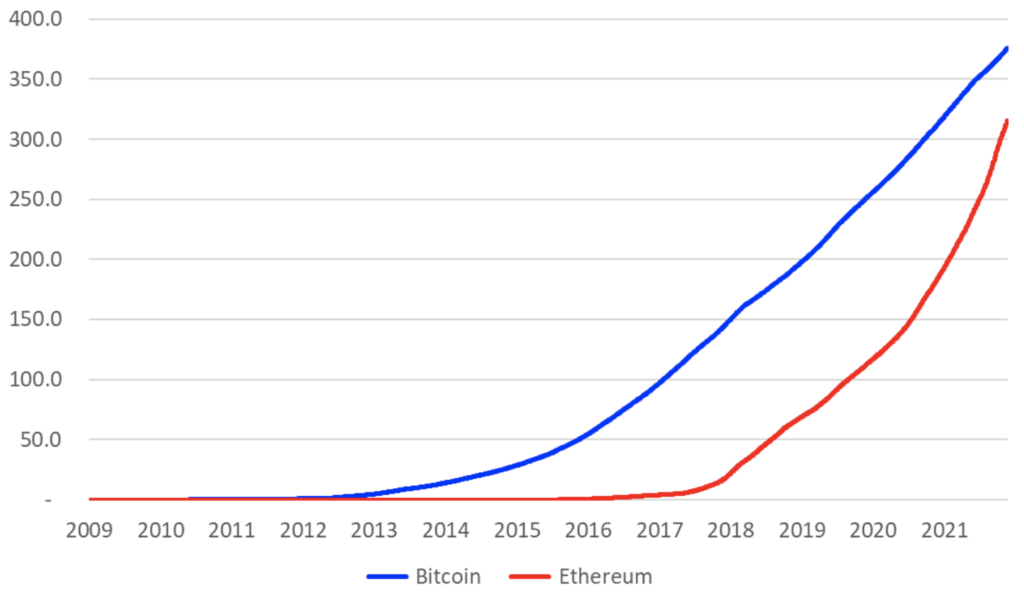
Source: BitMEX Research
In both cases, for Bitcoin and Ethereum, the total blockchain size in the chart above contains all transaction data, this is all the data one needs to download from one’s peers to fully synchronise and verify the chain. This includes all the digital signatures authorising each transaction. In the case of Ethereum and Geth we tested the inclusion of the signatures, by disconnecting our Geth node from the internet and successfully retrieving the digital signatures from various sample transactions, including ones from 2016 and 2017. The Ethereum blockchain data also includes all the code necessary to deploy every smart contract and we also tested the presence of this code on our local machine, which had a few hundred GB of storage.
What is the 9TB Ethereum blockchain?
As for the 9TB claim, this is likely to come from the Etherscan website here: https://etherscan.io/chartsync/chainarchive
This large dataset is for something called an “archival node”. As far as we can tell, this larger data size is because the node stores and indexes results from historic states of the network in memory. All these results can be calculated from the smaller blockchain data set. One can think of this large 9TB dataset as the amount of data required to follow the flow of funds at each point following on from Ethereum’s genesis. In that sense, it is an interesting metric and comparing this 9TB dataset with Bitcoin’s 400GB blockchain is reasonable.
When looking up a recent transaction hash on our non-archival Geth node with the following command, we obtained a successful result:
eth.getTransaction("TXHash")
However, if we try this same command for an older transaction we get a result of “null”, presumably because the transaction is not indexed. However, we can still obtain data from these older transactions by requesting their position in a particular block.
eth.getTransactionFromBlock("Block number", "Transaction Index")
The above command results in success, even for very old Ethereum transactions, when running a non-archival node with only a few hundred GB of storage data. The transaction signature is also displayed. For what it’s worth, as at 21 November 2021 our Geth node has 528GB of data in the chaindata directory. Of this 267GB is in the “ancient” folder, data related to older blocks.
Bitcoin UTXO set vs Ethereum head state
The next question that arises, follows on from Peter Szilagyi’s comment on Ethereum’s head state requiring 130GB of data. We received some questions on why this is so large compared to the somewhat equivalent or analogous metric in Bitcoin, the UTXO set size, the set of unspent Bitcoin outputs. The last block and the state head or UTXO set is all a node needs to assess the validity of an incoming block, in the case of Ethereum and Bitcoin respectively.
At the time of writing, Bitcoin’s UTXO set contains around 76 million outputs, taking up 4.6GB of disk space. Bitcoin Core supports pruning the blockchain, where a node can discard old blockchain data and only retain some very recent transactions plus the UTXO set. This means that one can fully validate the entire Bitcoin blockchain and check the validity of new blocks, with well under 10GB of disk space. This is a pretty neat feature and represents a strong efficiency. For instance, 4.6GB is only around 1.2% of the size of the entire Bitcoin blockchain.
This efficiency does not seem to apply to Ethereum. Using the figures quoted by Peter, the head state on Ethereum is 130GB, which is around 43% of the blockchain size, far higher than 1.2% on Bitcoin. Ethereum has old transactions and accounts, why can’t these also be pruned, at least in theory, resulting in this saving? It is fair to say that as far as we know, the Ethereum developers have not tried to make this more efficient, as there have been other priorities, but even if they did attempt this, they would be unlikely to achieve the efficiency savings that one can see in Bitcoin.
Ethereum’s state chain
In Ethereum there are two major types of databases stored by a node: The blockchain (all the transactions plus the block headers) and the state. The state is computed from the transaction history and essentially contains: all Ethereum account balances, storage associated with every deployed Ethereum smart contract and account nonces. The state is updated and computed after each block, based on the previous state and the new transactions in the block. A merkle root hash of the state is included in each block header, ensuring consensus of the network state. The state data continues to grow as Ethereum progresses and as mentioned above, the latest state is comparable in size to the blockchain itself. If a node was to store all the complete states, for every block, this would be a gigantic amount of data, perhaps significantly larger than even the 9TB archive node.
An individual Ethereum transaction could have a very small impact on the state or a large impact on the state. For instance a “regular” transaction that just sends Ethereum from one address to another will have a minimal impact on the state. At the same time, a transaction that fails because it runs out of gas, will also have a minimal impact on the state. In contrast, other types of transactions, which may have a small data footprint on the blockchain themselves, could have a large impact on the state, for instance one transaction could interact with a smart contract which could change multiple account balances. If the Ethereum blockchain contained only the transactions with a minimal impact on the state, then the state size would be far smaller and we could approach the c1% efficiency level seen with Bitcoin’s UTXO set.
This is the key difference between Bitcoin transactions and Ethereum transactions. Just by looking at an individual Bitcoin transaction you can tell the impact it has on the state of the Bitcoin network and you can see what is going on. With Ethereum, you cannot necessarily do this, with Ethereum you can normally only know what a transaction does by also computing the state of the entire network.
You may be thinking, ok so Ethereum works differently than Bitcoin, in that there is no clear link or relationship between the head state size and the number of transactions, but the same principles of pruning could still apply. Why can there not be part of the state that is old, unused or expired, that could be pruned and excluded from the head state? Ethereum does not really work like that. When smart contracts are deployed, there is never really any mechanism to close or end the contract, it just continues to exist forever, even if it is no longer used. Part of the core idea behind Ethereum is that it’s one interactive system where contracts are composable. Any account can interact with any smart contract or any part of the state at any time. In order to validate a new block, a node must therefore have the latest state of all the smart contracts and the entire system. Only limited pruning or efficiencies are therefore possible when it comes to reducing the size of the head state. The head state is therefore likley to continue to grow over time.
Bitcoin vs Ethereum Blockchain: Conclusion
The comparison between the blockchain size for Ethereum and Bitcoin is not always particularly relevant. The Bitcoin blockchain is mostly sufficient to tell you all you need to know about the Bitcoin network. In contrast, the Ethereum blockchain itself is by no means sufficient to tell you much about the state of Ethereum, to do this one needs to compute and store much more data, otherwise you don’t know what many of the transactions are actually doing. However, to be fair, one way in which the blockchain data size is comparison is somewhat relevant is the minimum amount of data you need to download over the internet to perform an initial synchronisation. By this metric, the two coins are pretty close and Ethereum is about to take the lead, or move into an inferior position, depending on how you look at it.